Latent GOLD
潜在クラス分析専用に最適化されたソフトウェア
使いやすい直感的なインターフェイス、高速な計算と解析が可能

潜在クラス分析とは
潜在クラス分析は、数値データ(量的データ)や数値でないデータ(質的データ)を含む様々な種類が混在するデータを統計的にグループ(クラス)分けをしてくれる手法で、属する一つのグループを決めるのではなく、複数のグループに属するあいまいさを認めている手法です。
潜在クラス分析には、次のような特長があります。
- 表面上観測される事象(※1)の関係性を説明するための、隠れた共通点(※2)の探索を行う因子分析的な側面を持ちます。
- 観測された事象の分類(クラス分け)を行うクラスター分析的な側面を持ちます。
- グループ(クラス)への所属を確率的に分類することができます。
- 統計情報に基づく基準でクラス分けを行うことができます。
- 質的データ(※3)・量的データ(※4)の両方を取り扱うことができ、分析に使える変数の自由度が高い手法と言えます。
※1観測変数といいます。観測変数とは、実際に表面上に現れる(観測される)変数(データや事象)を言います。
※2潜在変数といいます。潜在変数とは、表面上は見えない隠れた変数(データや事象)を言います。
※3質的データとは、データがカテゴリで示されるものを言います(データ間の「質」が違う変数です)。例えば、商品名、性別、国名、動物の名前などがあります。
※4量的データとは、データが数値で示されるものを言います。例えば、身長、年齢、面積、金額などがあります。
潜在クラス分析と因子分析の違い
潜在クラス分析も因子分析も、表面上観測される事象から、隠れた共通点を探し、グルーピングをするという分析手法です。この2つの分析手法には、次の違いがあります。
- 因子分析では、連続したデータ(数値)しか扱うことができません。
- 潜在クラス分析では、離散したデータや、質的データも扱うことができます。
このため、潜在クラス分析では量的変数も質的変数も含めて様々な種類のデータが混ざった状態での分析を行うことができます。潜在クラス分析は、非常に汎用性の高い分析手法だと言えるでしょう。
潜在クラス分析とクラスター分析の違い
クラスター分析では、距離(数値データ)を基に近いグルーピングを作ります(右図のa, b, c)。この距離は定義の仕方によってさまざまでそれによってグルーピングの結果も変わってきます。また、分類した結果は統計的な意味を持ちません。これに対して潜在クラス分析では、統計モデルを用いて分析を行うため、右図のA, Bのような分析結果をモデルとして扱うことができます。
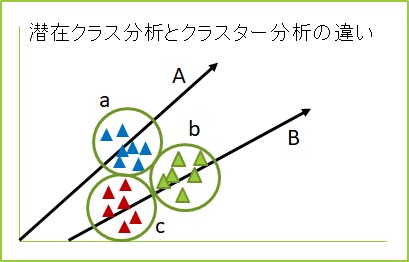
まとめると、次のような違いがあります。
- クラスター分析は距離(数値データ)を基にグルーピングを行いますが、潜在クラス分析ではグループ(クラス)への所属を確率的に分類します。
- クラスター分析の分類結果に統計的な意味は持ちませんが、潜在クラス分析では統計情報に基づく基準でクラス分けを行うことができます。
- クラスター分析は量的データしか扱うことができませんが、潜在クラス分析では質的データ・量的データの両方を取り扱うことができ、分析に使える変数の自由度が高いと言えます。
潜在クラス分析の例
ここではコンビニのPOSデータを想定した仮想データを使って、潜在クラス分析の流れを説明します。
POSデータには、顧客が一回の買い物でどのようなものを同時に購入したのかが記録されています。ここでは、7つの品目について同時購買に関する分析を行い、この情報に基づく顧客のセグメンテーションを考えます。
ある特定の商品を購入した来店者について、各商品の購入の有無を調べて、そのデータについて潜在クラス分析を行いました。なお、4000回分の購買データが分析対象となっています。
ここでは、クラスタモデルで潜在クラス分析の結果からどのようなことが分析できるか見てみます。
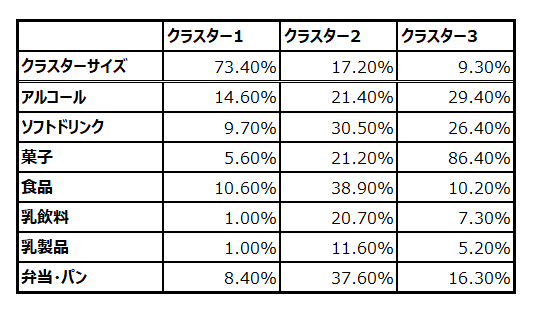
クラスタサイズは、各クラスタのサイズを表しており、例えば、クラスタ1の大きさは73.4%であると考えます。各変数についての数字は、各クラスタに属する顧客が各商品を購入する確率を表しています。例えば、クラスタ3の集団は、菓子を86.4%の確率で購入すると考えることができます。
このことを踏まえて、3つの潜在クラスの特徴をまとめると次のように考えることができます。
- クラスタ1:あまり商品を購入しない顧客群
- クラスタ2:弁当やパン類、食品と一緒にソフトドリンクなど飲料品も購入していると思われる顧客群
- クラスタ3:アルコール類、ソフトドリンク、お菓子などを同時購入してくれる顧客群
潜在クラス分析を行うことによって、この例のように顧客が各クラスタに属している可能性を示す指標が算出されます。
こうした潜在クラス分析を行うことで、膨大なデータの中からカテゴリーによって分類されたクラスが存在することを見出すことができます。
コンビニでのクラス分けの例を見てきましたが、分類したクラスを次のように活用することができます。
例えば、コンビニにお客さんが入ってきて、何か買って(もしくは何も買わないで)店を出ていきます。入ってきたお客さんがどういう行動をとるのか事前に予測できれば、それに合わせたアプローチをとることができる可能性が高まります。
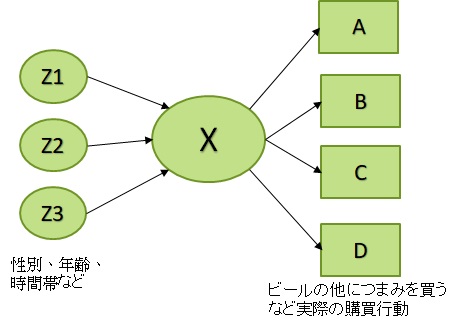
潜在クラス分析を使うと、性別、年齢、時間帯といったデータ(変数)から、パターンに分け(クラス分けし)、実際の行動を予測することができます。これを実際のマーケティングに活用することで購買率をあげられる可能性が高まります。
ここで潜在クラス分析についてまとめると、次のような手法ということができます。
①膨大なデータを商品の種類や個々の特性の違いなどから、統計的な手法をもとに複数のクラスター(クラス)に分けます。
②個々のデータはどのカテゴリーに所属するのかそれぞれ確率的に分類されます。
③クラスターをいくつに分けるのが妥当か判断し、各クラスターの特徴を分析します。
従来の手法と比べて、量的変数だけではなく質的変数も扱うことができ、膨大で複雑なデータを分類するのに優れた手法といえます。
潜在クラス分析の活用
マーケティング的には、表面上のデータからは見えない隠れたユーザーの嗜好などを探るための分析に使うことができます。例えば先ほどのコンビニの例に、時間や曜日、男女の区別、独身・既婚、住環境、駅からの距離など様々なデータを加えることで、従来のデータ分析では見えなかった傾向や嗜好を探ることも可能になります。
ヘルスケアや医療向けには、これまで考慮されなかった患者個別の要因(例えば独身か既婚か、子供がいるかなど)も織り込み、より精度の高いサービスの提供方法などを探るための手法として注目されています。